最近将公司的在线业务迁移到 Storm 集群上,上线后遇到低峰期 CPU 耗费严重的情况。在解决问题的过程中深入了解了 Storm 的内部实现原理,并且解决了一个 Storm 0.9-0.10版本一直存在的严重 bug,目前代码已经合并到了 Storm 新版本中,在这篇文章里会介绍这个问题出现的场景、分析思路、解决的方式和一些个人的收获。
背景
首先简单介绍一下 Storm,老司机可以直接跳过这段。 Storm 是 Twitter 开源的一个大数据处理框架,专注于流式数据的处理。Storm通过创建拓扑结构(Topology)来转换数据流。和 Hadoop 的作业(Job)不同,Topology 会持续转换数据,除非被集群关闭。 下图是一个简单的 Storm Topology 结构图。
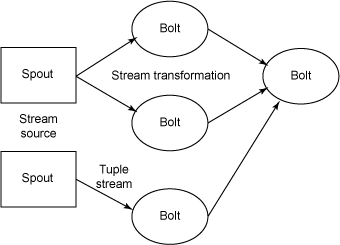
可以看出Topology是由不同组件(Component)串/并联形成的有向图。数据元组(Tuple)会在Component之间通过数据流的形式进行有向传递。Component有两种
- Spout:Tuple 来源节点,持续不断的产生Tuple,形成数据流
- Bolt:Tuple 处理节点,处理收到的 Tuple,如果有需要,也可以生成新的 Tuple 传递到其他 Bolt
目前业界主要在离线或者对实时性要求不高业务中使用 Storm。随着 Storm 版本的更迭,可靠性和实时性在逐渐增强,已经有运行在线业务的能力。因此我们尝试将一些实时性要求在百毫秒级的在线业务迁入Storm 集群。
现象
- 某次高峰时,Storm 上的一个业务拓扑频繁出现消息处理延迟。延时达到了 10s 甚至更高。查看高峰时的物理机指标监控,CPU、内存和 IO 都有很大的余量。判断是随着业务增长,服务流量逐渐增加,某个 Bolt 之前设置的并行度不够,导致消息堆积了。
- 临时增加该 Bolt 并行度,解决了延迟的问题,但是第二天的低峰期,服务突然报警,CPU 负载过高,达到了 100%。
排查
用 Top 看了下 CPU 占用,系统调用占用了 70% 左右。再用 wtool 对 Storm 的工作进程进行分析,找到了 CPU 占用最高的线程
java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x0000000640a248f8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2163) at com.lmax.disruptor.BlockingWaitStrategy.waitFor(BlockingWaitStrategy.java:87) at com.lmax.disruptor.ProcessingSequenceBarrier.waitFor(ProcessingSequenceBarrier.java:54) at backtype.storm.utils.DisruptorQueue.consumeBatchWhenAvailable(DisruptorQueue.java:97) at backtype.storm.disruptor$consume_batch_when_available.invoke(disruptor.clj:80) at backtype.storm.daemon.executor$fn__3441$fn__3453$fn__3500.invoke(executor.clj:748) at backtype.storm.util$async_loop$fn__464.invoke(util.clj:463) at clojure.lang.AFn.run(AFn.java:24) at java.lang.Thread.run(Thread.java:745)我们可以看到这些线程都在信号量上等待。调用的来源是
disruptor$consume_batch_when_available。disruptor 是 Storm 内部消息队列的封装。所以先了解了一下 Storm 内部的消息传输机制。
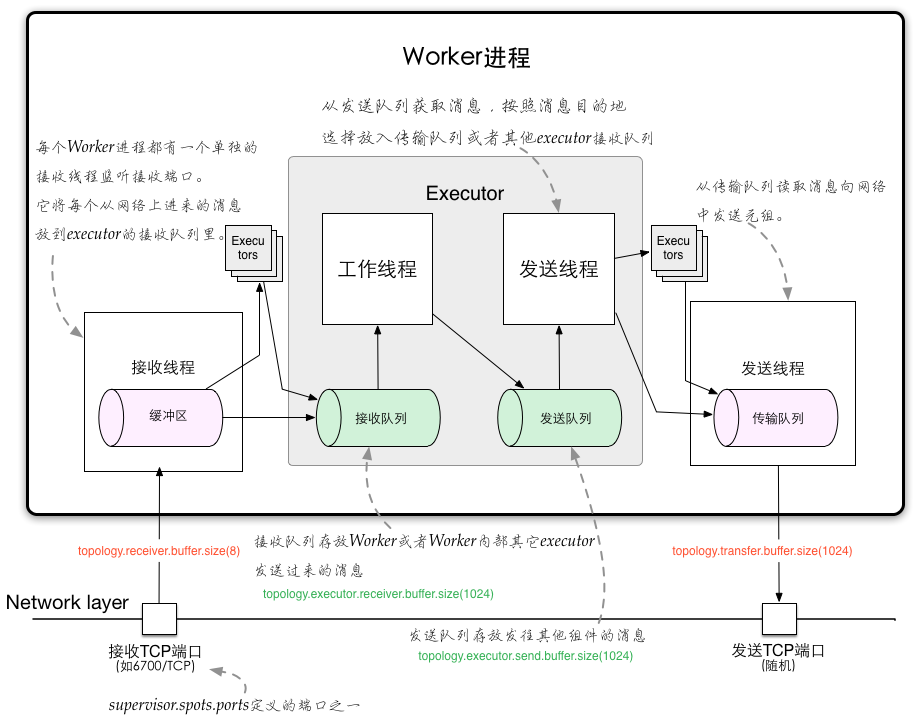 (图片来源Understanding the Internal Message Buffers of Storm)
(图片来源Understanding the Internal Message Buffers of Storm)Storm 的工作节点称为 Worker(其实就是一个JVM 进程)。不同 Worker 之间通过 Netty(旧版 Storm 使用 ZeroMQ)进行通讯。每个Worker 内部包含一组 Executor。Storm 会为拓扑中的每个 Component 都分配一个 Executor。在实际的数据处理流程中,数据以消息的形式在 Executor 之间流转。Executor 会循环调用绑定的 Component 的处理方法来处理收到的消息。 Executor 之间的消息传输使用队列作为消息管道。Storm 会给每个 Executor 分配两个队列和两个处理线程。
- 工作线程:读取接收队列,对消息进行处理,如果产生新的消息,会写入发送队列
- 发送线程:读取发送队列,将消息发送其他Executor
当Executor的发送线程发送消息时,会判断目标Executor是否在同一Worker内,如果是,则直接将消息写入目标Executor的接收队列,如果不是,则将消息写入Worker的传输队列,通过网络发送。 Executor工作/发送线程读取队列的代码如下,这里会循环调用consume-batch-when-available读取队列中的消息,并对消息进行处理。
(async-loop (fn [] ... (disruptor/consume-batch-when-available receive-queue event-handler) ... ))我们再来看一下
consume_batch_when_available这个函数里做了什么。(defn consume-batch-when-available [^DisruptorQueue queue handler] (.consumeBatchWhenAvailable queue handler))前面提到 Storm 使用队列作为消息管道。Storm 作为流式大数据处理框架,对消息传输的性能很敏感,因此使用了高效内存队列 Disruptor Queue 作为消息队列。
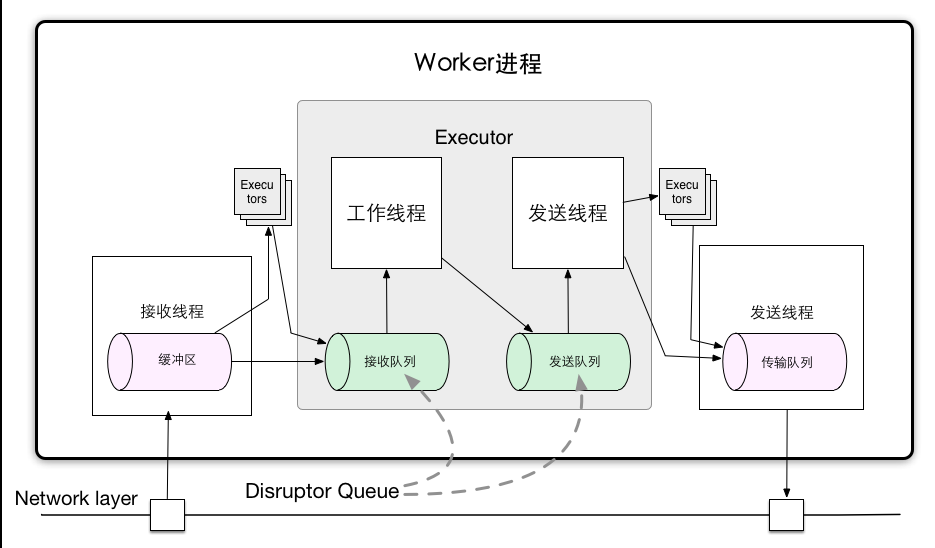
Disruptor Queue 是 LMAX 开源的一个无锁内存队列。内部实现如下。
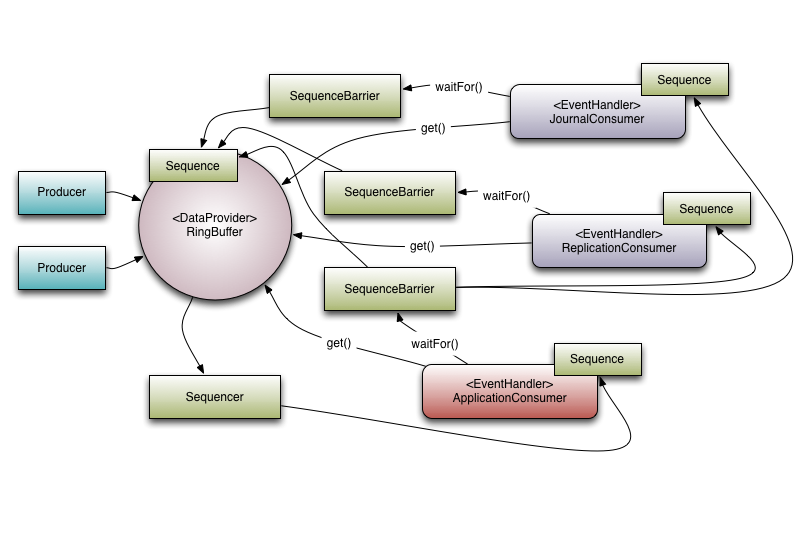
(图片来源 Disruptor queue Introduction)Disruptor Queue 通过 Sequencer 来管理队列,Sequencer 内部使用 RingBuffer 存储消息。RingBuffer 中消息的位置使用 Sequence 表示。队列的生产消费过程如下
- Sequencer 使用一个 Cursor 来保存写入位置。
- 每个 Consumer 都会维护一个消费位置,并注册到 Sequencer。
- Consumer 通过 SequenceBarrier 和 Sequencer 进行交互。Consumer 每次消费时,SequenceBarrier 会比较消费位置和 Cursor 来判断是否有可用消息:如果没有,会按照设定的策略等待消息;如果有,则读取消息,修改消费位置。
- Producer 在写入前会查看所有消费者的消费位置,在有可用位置时会写入消息,更新 Cursor。
查看
DisruptorQueue.consumeBatchWhenAvailable实现如下final long nextSequence = _consumer.get() + 1; final long availableSequence = _barrier.waitFor(nextSequence, 10, TimeUnit.MILLISECONDS); if (availableSequence >= nextSequence) { consumeBatchToCursor(availableSequence, handler); }继续查看
_barrier.waitFor方法public long waitFor(final long sequence, final long timeout, final TimeUnit units) throws AlertException, InterruptedException { checkAlert(); return waitStrategy.waitFor(sequence, cursorSequence, dependentSequences, this, timeout, units); }Disruptor Queue 为消费者提供了若干种消息等待策略
BlockingWaitStrategy:阻塞等待,CPU 占用小,但是会切换线程,延迟较高BusySpinWaitStrategy:自旋等待,CPU 占用高,但是无需切换线程,延迟低YieldingWaitStrategy:先自旋等待,然后使用 Thread.yield() 唤醒其他线程,CPU 占用和延迟比较均衡SleepingWaitStrategy:先自旋,然后Thread.yield(),最后调用LockSupport.parkNanos(1L),CPU 占用和延迟比较均衡
Storm 的默认等待策略为
BlockingWaitStrategy。BlockingWaitStrategy的waitFor函数实现如下if ((availableSequence = cursor.get()) < sequence) { lock.lock(); try { ++numWaiters; while ((availableSequence = cursor.get()) < sequence) { barrier.checkAlert(); if (!processorNotifyCondition.await(timeout, sourceUnit)) { break; } } } finally { --numWaiters; lock.unlock(); } }BlockingWaitStrategy内部使用信号量来阻塞 Consumer,当 await 超时后,Consumer 线程会被自动唤醒,继续循环查询可用消息。- 而
DisruptorQueue.consumeBatchWhenAvailable方法中可以看到,Storm 此处设置超时为 10ms。推测在没有消息或者消息量较少时,Executor 在消费队列时会被阻塞,由于超时时间很短,工作线程会频繁超时,consumeBatchWhenAvailable会被频繁调用,导致 CPU 占用飙高。尝试将 10ms 修改成 100ms,编译 Storm 后重新部署集群,使用 Storm 的 demo 拓扑,将 bolt 并发度调到 1000,修改 spout 代码为 10s 发一条消息。经测试 CPU 占用大幅减少。再将 100ms 改成 1s,测试 CPU 占用基本降为零。 但是随着调高超时,测试时并没有发现消息处理有延时。继续查看
BlockingWaitStrategy代码,发现 Disruptor Queue 的 Producer 在写入消息后会唤醒等待的 Consumer。if (0 != numWaiters) { lock.lock(); try { processorNotifyCondition.signalAll(); } finally { lock.unlock(); } }这样,Storm 的 10ms 超时就很奇怪了,没有减少消息延时,反而增加了系统负载。带着这个疑问查看代码的上下文,发现在构造
DisruptorQueue对象时有这么一句注释;; :block strategy requires using a timeout on waitFor (implemented in DisruptorQueue), as sometimes the consumer stays blocked even when there's an item on the queue. (defnk disruptor-queue [^String queue-name buffer-size :claim-strategy :multi-threaded :wait-strategy :block] (DisruptorQueue. queue-name ((CLAIM-STRATEGY claim-strategy) buffer-size) (mk-wait-strategy wait-strategy)))Storm 使用的 Disruptor Queue 版本为2.10.1。查看 Disruptor Queue 的change log,发现该版本的
BlockingWaitStrategy有潜在的并发问题,可能导致某条消息在写入时没有唤醒等待的消费者。2.10.2 Released (21-Aug-2012)
- Bug fix, potential race condition in BlockingWaitStrategy.
- Bug fix set initial SequenceGroup value to -1 (Issue #27).
- Deprecate timeout methods that will be removed in version 3.
因此 Storm 使用了短超时,这样在出现并发问题时,没有被唤醒的消费方也会很快因为超时重新查询可用消息,防止出现消息延时。 这样如果直接修改超时到 1000ms,一旦出现并发问题,最坏情况下消息会延迟 1000ms。在权衡性能和延时之后,我们在 Storm 的配置文件中增加配置项来修改超时参数。这样使用者可以自己选择保证低延时还是低 CPU 占用率。
- 就
BlockingWaitStrategy的潜在并发问题咨询了Disruptor Queue的作者,得知2.10.4版本已经修复了这个并发问题(Race condition in 2.10.1 release )。将 Storm 依赖升级到此版本。但是对 Disruptor Queue 的 2.10.1 做了并发测试,无法复现这个并发问题,因此也无法确定 2.10.4 是否彻底修复。谨慎起见,在升级依赖的同时保留了之前的超时配置项,并将默认超时调整为 1000ms。经测试,在集群空闲时 CPU 占用正常,并且压测也没有出现消息延时。
总结
- 关于集群空闲CPU反而飙高的问题,已经向Storm社区提交PR并且已被接受 [STORM-935] Update Disruptor queue version to 2.10.4。在线业务流量通常起伏很大,如果被这个问题困扰,可以考虑应用此 patch。
- Storm UI 中可以看到很多有用的信息,但是缺乏记录,最好对其进行二次开发(或者直接读取 ZooKeeper 中信息),记录每个时间段的数据,方便分析集群和拓扑运行状况。